SSVAE-Based Latent Control Mapping for Assistive Robotic Interfaces
Structured generative models for real-time user intent embedding and control-space customization
Andrew Thompson, Fiona Neylon, Brenna Argall | Northwestern University + Shirley Ryan AbilityLab
Overview
This project explores the use of variational autoencoders (VAEs) to learn structured latent control spaces from body-machine interface (BoMI) data. The goal is to enable intuitive, low-dimensional user intent embeddings that generalize across users and time, and to support robust control of high-dimensional robotic systems from sparse or noisy human input.
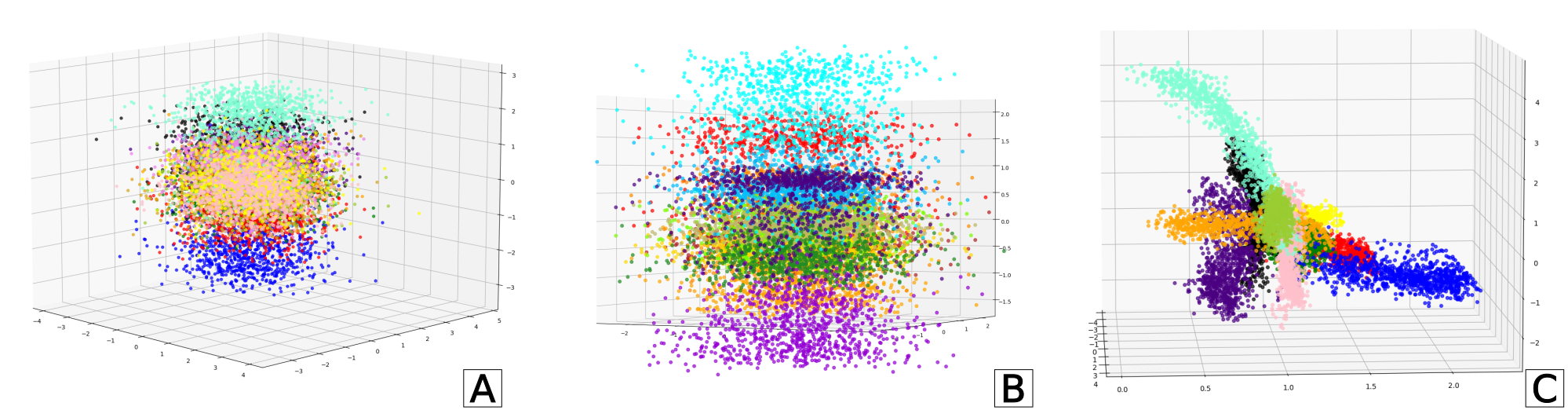
Unlike PCA-based mappings used during deployment, the SSVAE-based approach is generative and probabilistic. It allows for intent inference under uncertainty, meaningful and continuous interpolation across embeddings, and latent-level customization—capabilities that support safer and more generalizable assistive control.
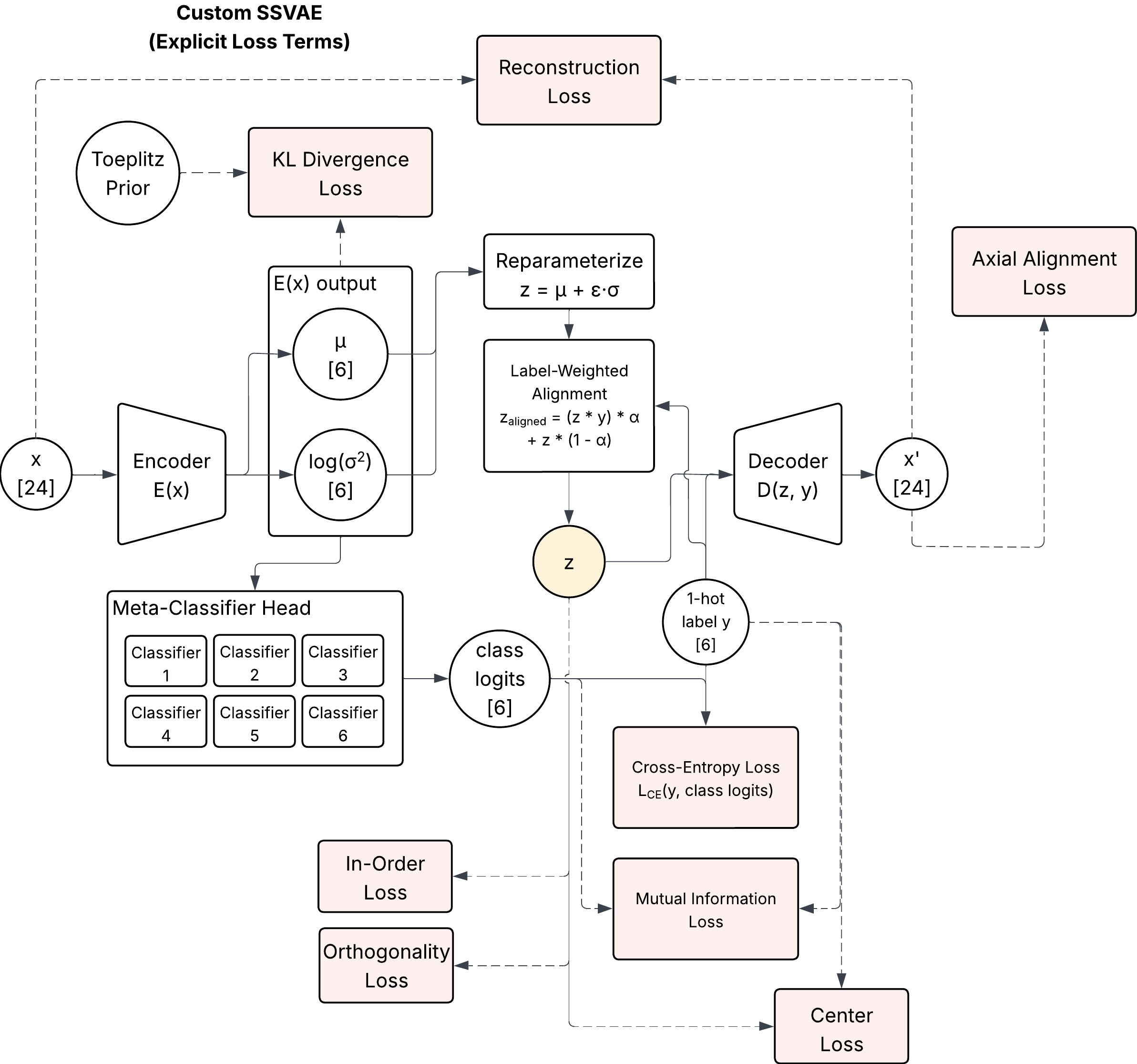
Motivation
- Improve robustness of control mappings to signal drift, fatigue, and inter-user variability.
- Reduce calibration overhead by learning generalized motion embeddings across users.
- Enable few-shot or zero-shot transfer of control strategies between sessions or individuals.
- Capture control uncertainty to improve shared autonomy, safety, and intent disambiguation.
System Design
Architecture
- Input: 8–24 channel filtered IMU signals or joystick control time windows
- Encoder: 3-layer MLP with ReLU activations, layer norm
- Latent space: 2–6D Gaussian embedding (μ, σ) with KLD penalty
- Decoder: Symmetric 3-layer MLP; reconstructs control signals or time-aligned action vectors
- Loss: ELBO with optional auxiliary losses (e.g., latent decorrelation, temporal smoothness)
Training Pipeline
- Data sampled from longitudinal BoMI sessions (~190 total)
- Signals preprocessed with filtering, windowing, and normalization
- Models trained with PyTorch, Adam optimizer, and cosine learning rate decay
- Evaluation on reconstruction accuracy, latent smoothness, and downstream control decoding
Experiments
| Experiment | Goal | Outcome |
|---|---|---|
| Latent stability across sessions | Assess how latent axes shift with session index | Axes remain consistent across 3+ sessions with single-user training |
| Cross-user generalization | Train on one user, test on another | Latents retain structure, but decoder needs fine-tuning |
| Control-space mapping | Latent → 6-DOF robot control mapping | Mapping feasible with linear decoder or MLP; interpretable axes emerge |
| Few-shot retraining | Fine-tune encoder with small new-user dataset | Rapid convergence observed with 20–50 examples |
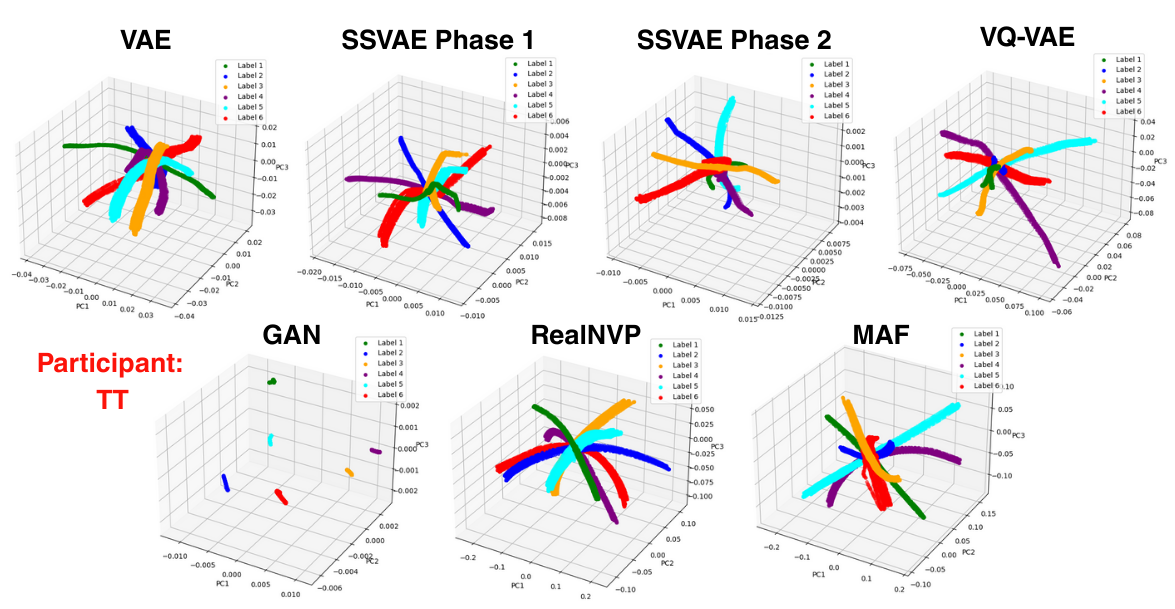
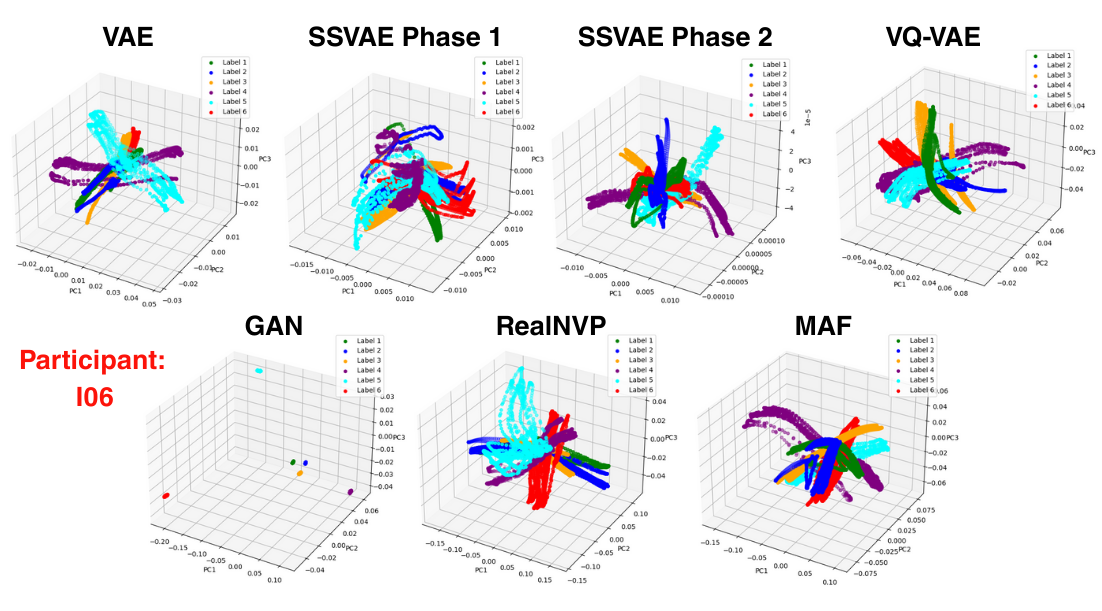
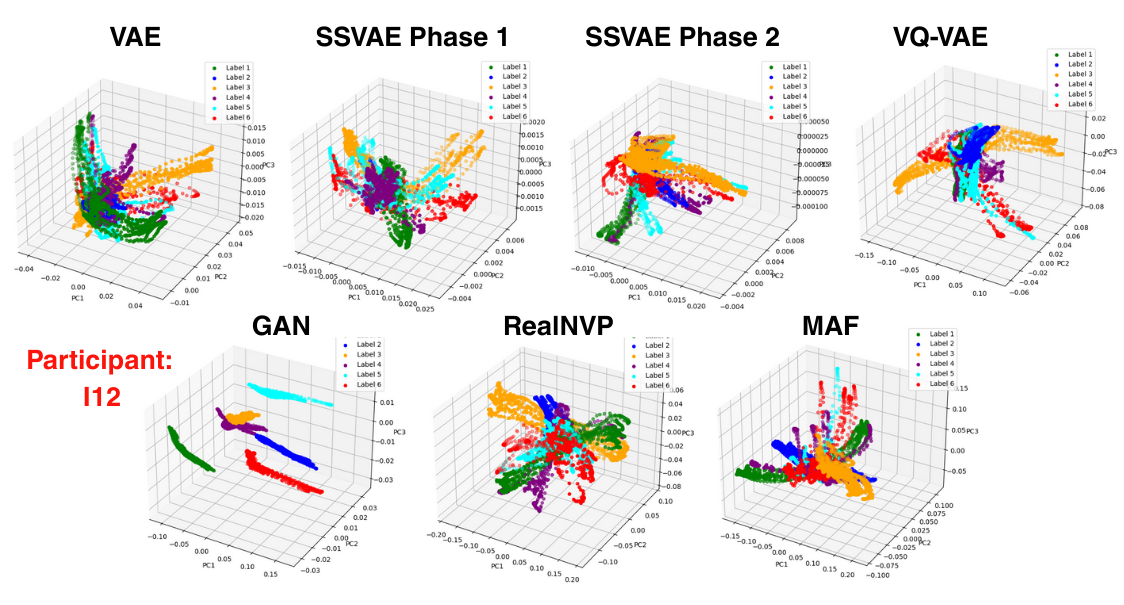
Key Insights
- VAE-based latents capture user-specific movement signatures in a compact and reusable form.
- Latent spaces are smoother and more robust than PCA in the presence of sensor noise or posture shift.
- The probabilistic nature of the model supports uncertainty-aware intent prediction, which is valuable for shared autonomy systems.
- While not yet deployed in real-time trials, offline control decoding from the latent space has yielded promising results.
Additionally, ablation studies were on all of the additional cost terms to see their effect.
Relation to PCA-Based BoMI Deployment
This work builds directly on the PCA-based BoMI system used in a 190+ session longitudinal study, where we gathered data from and evaluated teleoperation performance from a cohort of 10 individuals with cervical spinal cord injuries (cSCI). The SSVAE model was trained entirely on data collected during those sessions. Whereas PCA was used for control deployment, the SSVAE supports:
- Post hoc analysis of motor strategies
- Improved control personalization
- Future real-time deployment with adaptive blending
Ongoing Work
- Incorporating temporal priors (e.g. LSTM-VAE, temporal VAE) to model motion transitions
- Conditioning latent space with goal or task context
- Real-time latent encoding + ROS2 interface for on-device teleoperation
- Ablation studies on dimensionality, loss structure, and encoder architecture
Citation
Preprint (In Review):
Structured Semi-Supervised Generative Methods for Learning Robust Control Embeddings from Human Motion Data
Andrew Thompson, Fiona Neylon, Brenna Argall
Access
All models and training scripts are currently housed in private repositories. Code excerpts, latent visualizations, and sanitized motion samples are available upon request.